import cfbd
from cfbd.rest import ApiException
from cfbd.models.team_record import TeamRecord
import pandas as pd
from pandas import json_normalize
import matplotlib.pyplot as plt
from matplotlib.offsetbox import OffsetImage, AnnotationBbox
import numpy as np
import seaborn as snsCollege football has experienced monumental changes over the last six and a half years since the launch of the NCAA Transfer Portal. Combined with the advent of (legalized) Name, Image, and Likeness payments, collegiate athletes now have unprecedented levels of autonomy over their careers. Proponents of The Portal laud the addition for allowing players to be treated like professional athletes and be compensated according to their fair market values. Collegiate athletics are a multi-billion dollar industry after all. Critics say that it is ruining the sport by eroding tradition and watering down, if not removing entirely, the student portion of student athlete.
If you are looking for another blog with some takes about whether or not the transfer portal is good for The Sport™, there are plenty of those elsewhere. I’m interested in seeing how much roster turnover and, by extension, the Transfer Portal matters for team success.
I’m particularly interested in the Non-Power Conference teams. One of the biggest criticisms from the people most affected by the Transfer Portal is that the lower level teams get picked clean by the bigger programs each off-season. I want to see if that is true and, if it is, to what effect.
I’m pulling data from the cfbd-python library for this post. If you like college football, this API is a must for your data analysis. A note on the API: you must sign up for an API key in order to use this it. It is very easy to get one and it is generally sent out very quickly after you sign up. I have a cell block hidden below my imports that configures my API key so I can make requests, so you will not be able to replicate my code simply from copying and pasting. Follow the documentation to configure your API and you’ll be golden.
client = cfbd.ApiClient(configuration)
teams_api = cfbd.TeamsApi(client)
players_api = cfbd.PlayersApi(client)
games_api = cfbd.GamesApi(client)
players_api = cfbd.PlayersApi(client)
records_response = []
transfer_response = []
try:
teams_response = teams_api.get_fbs_teams() # Get a list of all FBS teams
for year in range(2021, 2025): # Get data for 2021-2024
records_response += games_api.get_records(year=year) # Team records
transfer_response += players_api.get_transfer_portal(year=year) # Transfer players
except ApiException as e:
print("Exception when calling StatsApi->get_stats_seasons: %s\n" % e)
print("Status code: %s" % e.status)
# Data response comes as object, we need to convert them to dictionaries
team_dicts = [vars(team) for team in teams_response]
teams_df = pd.DataFrame(team_dicts)
records_dicts = [vars(record) for record in records_response]
records_df = pd.DataFrame(records_dicts)
transfer_dicts = [vars(transfer) for transfer in transfer_response]
transfer_df = pd.DataFrame(transfer_dicts)This dataframe gets us a list of all FBS college football teams.
teams_df.head()| id | school | mascot | abbreviation | alternate_names | conference | division | classification | color | alternate_color | logos | location | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2005 | Air Force | Falcons | AFA | [AFA, Air Force] | Mountain West | None | fbs | #004a7b | #ffffff | [http://a.espncdn.com/i/teamlogos/ncaa/500/200... | @AF_Football | id=3713 name='Falcon Stadium' city='Colorado S... |
| 1 | 2006 | Akron | Zips | AKR | [AKR, Akron] | Mid-American | None | fbs | #00285e | #84754e | [http://a.espncdn.com/i/teamlogos/ncaa/500/200... | @ZipsFB | id=3768 name='InfoCision Stadium' city='Akron'... |
| 2 | 333 | Alabama | Crimson Tide | ALA | [ALA, Alabama] | SEC | None | fbs | #9e1632 | #ffffff | [http://a.espncdn.com/i/teamlogos/ncaa/500/333... | @AlabamaFTBL | id=3657 name='Bryant-Denny Stadium' city='Tusc... |
| 3 | 2026 | App State | Mountaineers | APP | [Appalachian State, APP, App State] | Sun Belt | East | fbs | #ffcc00 | #222222 | [http://a.espncdn.com/i/teamlogos/ncaa/500/202... | @AppState_FB | id=3792 name='Kidd Brewer Stadium' city='Boone... |
| 4 | 12 | Arizona | Wildcats | ARIZ | [ARIZ, Arizona] | Big 12 | None | fbs | #0c234b | #ab0520 | [http://a.espncdn.com/i/teamlogos/ncaa/500/12.... | @ArizonaFBall | id=3619 name='Arizona Stadium' city='Tucson' s... |
Get the records for each team each season.
def extract_attributes(team_record):
if hasattr(team_record, '_dict__'):
return pd.Series(team_record.__dict__)
return pd.Series()
nested_columns = ['total', 'conference_games', 'home_games',
'away_games', 'neutral_site_games', 'regular_season', 'postseason']
expanded_dataframes = []
for col in nested_columns:
expanded_df = records_df[col].apply(extract_attributes)
expanded_df = expanded_df.add_prefix(f"{col}_")
expanded_dataframes.append(expanded_df)
records_df = pd.concat([records_df] + expanded_dataframes, axis=1)
records_df = records_df.drop(columns=nested_columns)
records_df.head()| year | team_id | team | classification | conference | division | expected_wins | |
|---|---|---|---|---|---|---|---|
| 0 | 2021 | 2 | Auburn | DivisionClassification.FBS | SEC | West | 6.267284 |
| 1 | 2021 | 2169 | Delaware State | DivisionClassification.FCS | MEAC | NaN | |
| 2 | 2021 | 2447 | Nicholls | DivisionClassification.FCS | Southland | 0.780959 | |
| 3 | 2021 | 2487 | Pace | DivisionClassification.II | Northeast 10 | NaN | |
| 4 | 2021 | 2823 | Northwestern Oklahoma State | DivisionClassification.II | Great American | NaN |
transfer_df.head()| season | first_name | last_name | position | origin | destination | transfer_date | rating | stars | eligibility | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2021 | Cameron | Wilkins | LB | Missouri | UTSA | 2021-07-31 14:46:00+00:00 | NaN | 3.0 | TransferEligibility.IMMEDIATE |
| 1 | 2021 | Stephon | Wright | DL | Arizona State | SMU | 2021-07-29 15:50:00+00:00 | NaN | 4.0 | TransferEligibility.IMMEDIATE |
| 2 | 2021 | Javar | Strong | S | Arkansas State | None | 2021-07-28 15:25:00+00:00 | NaN | 3.0 | TransferEligibility.IMMEDIATE |
| 3 | 2021 | Noah | Mitchell | LB | UTSA | None | 2021-07-27 15:22:00+00:00 | NaN | 3.0 | TransferEligibility.IMMEDIATE |
| 4 | 2021 | Trivenskey | Mosley | RB | Southern Miss | None | 2021-07-26 00:00:00+00:00 | NaN | 3.0 | TransferEligibility.TBD |
And finally, get the number of incoming transfers for a season. These are grouped based on transfer date. Because the transfer portal windows are all in the same year in which a season is played, we do not need to lag this by a year. For example, if a player transfers in May of 2025, he would be eligible to play for the fall 2025 season.
transfers_in = (
transfer_df.groupby(['destination', 'season'])
.size()
.reset_index(name='total_transfers_in')
)
transfers_out = (
transfer_df.groupby(['origin', 'season'])
.size()
.reset_index(name='total_transfers_out')
)
transfer_df = (
pd.merge(
transfers_in, transfers_out,
left_on=['destination', 'season'],
right_on=['origin', 'season'],
how='outer'
)
)
transfer_df.head()| destination | season | total_transfers_in | origin | total_transfers_out | |
|---|---|---|---|---|---|
| 0 | Abilene Christian | 2021 | 4.0 | Abilene Christian | 2.0 |
| 1 | Abilene Christian | 2022 | 9.0 | Abilene Christian | 4.0 |
| 2 | Abilene Christian | 2023 | 4.0 | Abilene Christian | 2.0 |
| 3 | Abilene Christian | 2024 | 13.0 | Abilene Christian | 2.0 |
| 4 | Air Force | 2021 | 2.0 | Air Force | 4.0 |
Combine them all together and…
# Combine data frames with a series of merges
df = teams_df.merge(records_df.set_index('team_id'), how="inner",
left_on=['id'], right_on=['team_id'])
df = df.merge(transfer_df, how='left',
left_on=['school', 'year'], right_on=['destination', 'season'])
#Get rid of columns that were duplicated in the merges and others that are not needed
df = df.loc[:, ~df.columns.str.endswith('y')
& ~df.columns.str.contains('alt_name')
& ~df.columns.str.contains('discriminator')
& ~df.columns.str.contains('configuration')]
for col in df.columns:
if col.endswith('_x'):
df.rename(columns={col: col[:-2]}, inplace=True)
df.head()| id | school | mascot | abbreviation | alternate_names | conference | division | classification | color | alternate_color | ... | location | year | team | expected_wins | destination | season | total_transfers_in | origin | total_transfers_out | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2005 | Air Force | Falcons | AFA | [AFA, Air Force] | Mountain West | None | fbs | #004a7b | #ffffff | ... | @AF_Football | id=3713 name='Falcon Stadium' city='Colorado S... | 2021 | Air Force | 10.097382 | Air Force | 2021.0 | 2.0 | Air Force | 4.0 |
| 1 | 2005 | Air Force | Falcons | AFA | [AFA, Air Force] | Mountain West | None | fbs | #004a7b | #ffffff | ... | @AF_Football | id=3713 name='Falcon Stadium' city='Colorado S... | 2022 | Air Force | 10.945056 | NaN | NaN | NaN | NaN | NaN |
| 2 | 2005 | Air Force | Falcons | AFA | [AFA, Air Force] | Mountain West | None | fbs | #004a7b | #ffffff | ... | @AF_Football | id=3713 name='Falcon Stadium' city='Colorado S... | 2023 | Air Force | 10.725707 | NaN | NaN | NaN | NaN | NaN |
| 3 | 2005 | Air Force | Falcons | AFA | [AFA, Air Force] | Mountain West | None | fbs | #004a7b | #ffffff | ... | @AF_Football | id=3713 name='Falcon Stadium' city='Colorado S... | 2024 | Air Force | 6.003888 | NaN | NaN | NaN | NaN | NaN |
| 4 | 2006 | Akron | Zips | AKR | [AKR, Akron] | Mid-American | None | fbs | #00285e | #84754e | ... | @ZipsFB | id=3768 name='InfoCision Stadium' city='Akron'... | 2021 | Akron | 2.934194 | Akron | 2021.0 | 3.0 | Akron | 14.0 |
5 rows × 21 columns
…voila! We have something that we can more easily work with now.
Exploratory Data Analysis
Before going looking at how transfer are affecting production, I want to get more familiar with the data set and see if we can learn anything interesting in there.
Code
transfers_by_season = df[['year', 'total_transfers_in']].groupby('year').sum().reset_index()
transfers_by_season['pct_change'] = transfers_by_season['total_transfers_in'].pct_change() * 100
plt.figure(figsize=(12, 7))
bars = plt.bar(transfers_by_season['year'], transfers_by_season['total_transfers_in'], color='#012d69')
for i, bar in enumerate(bars):
if i > 0:
pct_change = transfers_by_season['pct_change'].iloc[i]
label = f"\u25B2 {pct_change:.1f}%"
plt.text(bar.get_x() + bar.get_width() / 2, bar.get_height() + 10, label, ha='center', va='bottom', color='green')
plt.xticks(ticks=transfers_by_season['year'])
plt.xlabel('Season')
plt.ylabel('Total Transfers')
plt.title('Transfers In Across FBS From 2021-2024')Text(0.5, 1.0, 'Transfers In Across FBS From 2021-2024')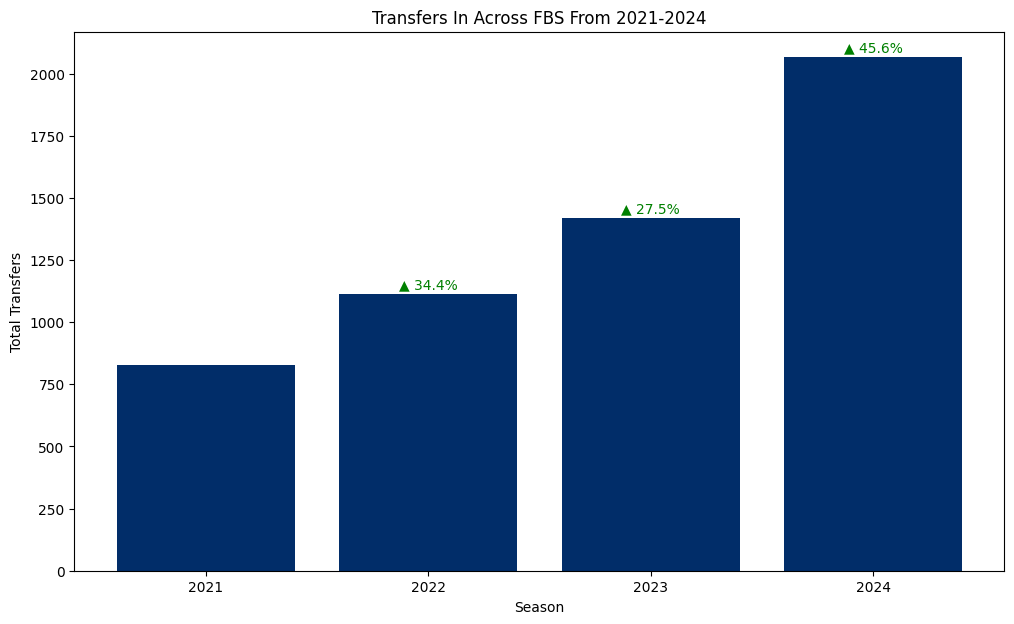
Transfers have increased year over year each year this decade with no real signs of slowing down. Whatever effect is made from this new Transfer Portal is likely to continue to grow moving forward until some sort of equilibrium is found.
But where are these transfers going?
Code
transfers_in_by_conference = df[['conference', 'total_transfers_in']].groupby('conference').sum().reset_index()
power_conferences = ['ACC', 'Big 12', 'Big Ten', 'Pac-12', 'SEC']
plt.figure(figsize=(12, 7))
colors = ['#ad0004' if conference in power_conferences else '#012d69' for conference in transfers_in_by_conference['conference']]
bars = plt.bar(transfers_in_by_conference['conference'], transfers_in_by_conference['total_transfers_in'], color=colors)
for i, bar in enumerate(bars):
transfers = bar.get_height().astype(int)
plt.text(bars[i].get_x() + bars[i].get_width() / 2, bars[i].get_height() + 10, transfers,
ha='center', va='bottom', color='black')
plt.xticks(rotation=45)
plt.xlabel('Conference')
plt.ylabel('Total Transfers')
plt.title('Transfers In by FBS Conference')Text(0.5, 1.0, 'Transfers In by FBS Conference')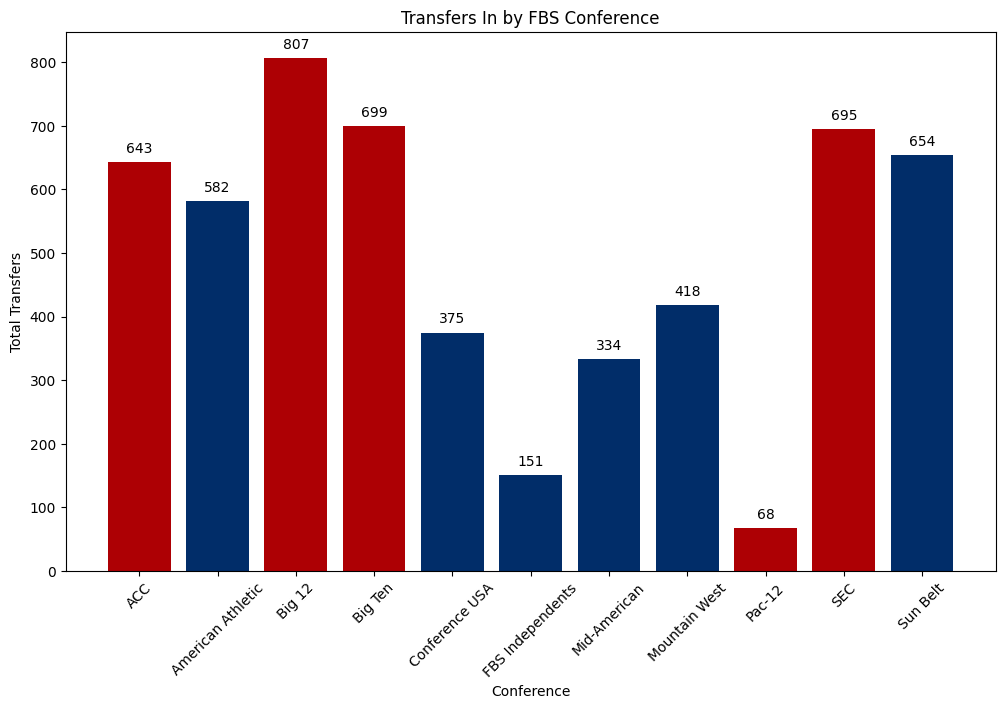
This chart surprises me a bit. I would have expected that all of the Power Five conferences would be head and shoulders above all of the Group of Five conferences. In reality, the top end of G5 conferences are getting nearly as many transfers, if not more, than the Power Five conferences. Also, what are they doing in the AAC?
A quick point about conference realignment: because our data is up to the 2024 offseason, teams that played their first season in their new conference in 2024 are still counted towards their original conference. If they played a season in their new conference prior to 2024, those changes are accurately reflected. For example, all Washington and Oregon data still count towards the Pac-12, all Texas and Oklahoma data still count towards the Big 12. But 2021-2023 BYU counts towards FBS Independents, but 2024 BYU counts towards the Big 12.
Code
transfers = pd.DataFrame(transfer_dicts) # Remake transfers data frame without aggregation
transfers = transfers.groupby('destination').agg({'stars': 'mean', 'season': 'count'}).rename({'season': 'total_transfers_in', 'stars': 'avg_stars'}, axis=1).reset_index()
transfers = transfers.merge(teams_df[['id', 'school', 'conference']], how='inner', left_on=['destination'], right_on=['school']).drop('school', axis=1)
power_five_transfers = transfers[transfers['conference'].isin(power_conferences) | transfers['destination'].str.contains('Notre Dame')]
g5_transfers = transfers[~transfers['conference'].isin(power_conferences) & ~transfers['destination'].str.contains('Notre Dame')]
# Function to get logos from image folder. Variable 'logos_folder' is defined in the hidden cell
# with API config. It is a local file path
def get_image_path(id):
return OffsetImage(plt.imread(f"{logos_folder}/{id}.png"))
# Scatter plots
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12, 7))
ax[0].scatter(power_five_transfers['avg_stars'], power_five_transfers['total_transfers_in'], alpha=0)
# Bind logo to data point
for x0, y0, id in zip(power_five_transfers['avg_stars'], power_five_transfers['total_transfers_in'], power_five_transfers['id']):
ab = AnnotationBbox(get_image_path(id), (x0, y0), frameon=False)
ax[0].add_artist(ab)
ax[0].axvline(power_five_transfers['avg_stars'].mean(), color='gray', linestyle='--')
ax[0].axhline(power_five_transfers['total_transfers_in'].mean(), color='gray', linestyle='--')
ax[0].set_xlabel('Average Stars')
ax[0].set_ylabel('Total Transfers In')
ax[0].set_xlim(2.7, 3.7)
ax[0].set_ylim(0, 105)
ax[0].set_title('Power Five Transfers In (2021-2024)')
ax[0].grid(True)
ax[1].scatter(g5_transfers['avg_stars'], g5_transfers['total_transfers_in'], alpha=0)
for x0, y0, id in zip(g5_transfers['avg_stars'], g5_transfers['total_transfers_in'], g5_transfers['id']):
ab = AnnotationBbox(get_image_path(id), (x0, y0), frameon=False)
ax[1].add_artist(ab)
ax[1].axvline(g5_transfers['avg_stars'].mean(), color='gray', linestyle='--')
ax[1].axhline(g5_transfers['total_transfers_in'].mean(), color='gray', linestyle='--')
ax[1].set_xlabel('Average Stars')
ax[1].set_ylabel('Total Transfers In')
ax[1].set_xlim(2.7, 3.7)
ax[1].set_ylim(0, 105)
ax[1].set_title('G5 Transfers In (2021-2024)')
ax[1].grid(True)
plt.show()
# Distribution plots
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12, 7))
sns.histplot(power_five_transfers['total_transfers_in'], label="Power 5", kde=True, color='#ad0004', alpha=0.5, ax=ax[0])
sns.histplot(g5_transfers['total_transfers_in'], label="G5", kde=True, color='#012d69', alpha=0.5, ax=ax[0])
ax[0].set_xlabel("Total Transfers")
ax[0].set_ylabel("Density")
ax[0].set_title("Distribution of Total Transfers In")
sns.histplot(power_five_transfers['avg_stars'], label="Power 5", kde=True, color='#ad0004', alpha=0.5, ax=ax[1])
sns.histplot(g5_transfers['avg_stars'], label="G5", kde=True, color='#012d69', alpha=0.5, ax=ax[1])
ax[1].set_xlabel("Average Stars")
ax[1].set_ylabel("Density")
ax[1].set_title("Distribution of Transfer In Star Ratings")
plt.legend()
plt.show()
# Calculate effect power for average stars
n_power_five = len(power_five_transfers)
n_g5 = len(g5_transfers)
std_power_five = power_five_transfers['avg_stars'].std()
std_g5 = g5_transfers['avg_stars'].std()
pooled_std = np.sqrt(((n_power_five - 1) * std_power_five**2 + (n_g5 - 1) * std_g5**2) / (n_power_five + n_g5 - 2))
cohens_d = (power_five_transfers['avg_stars'].mean() - g5_transfers['avg_stars'].mean()) / pooled_std
print(f"Cohen's D: {cohens_d:.2f}")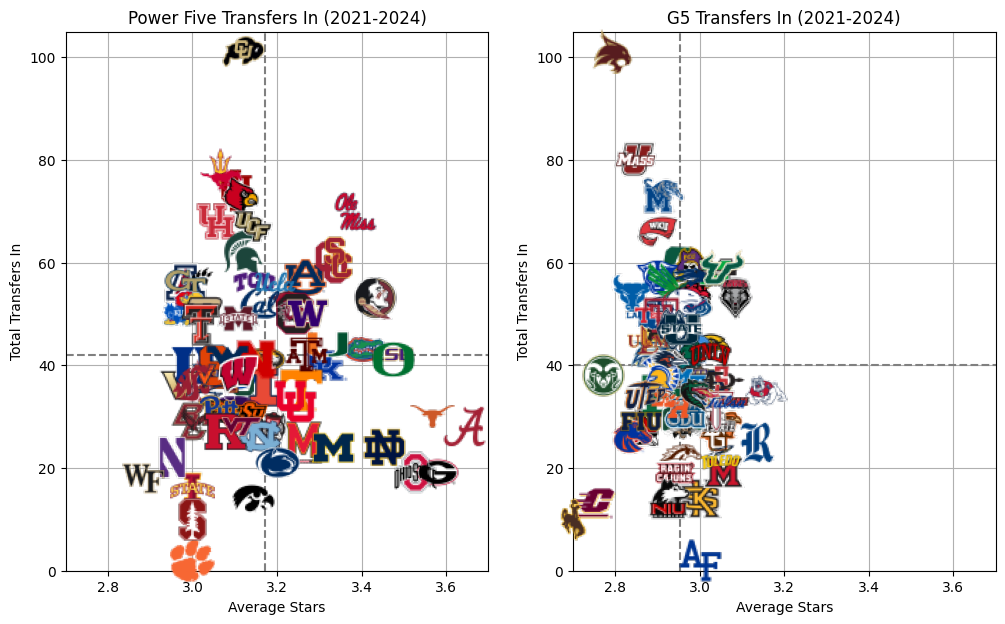
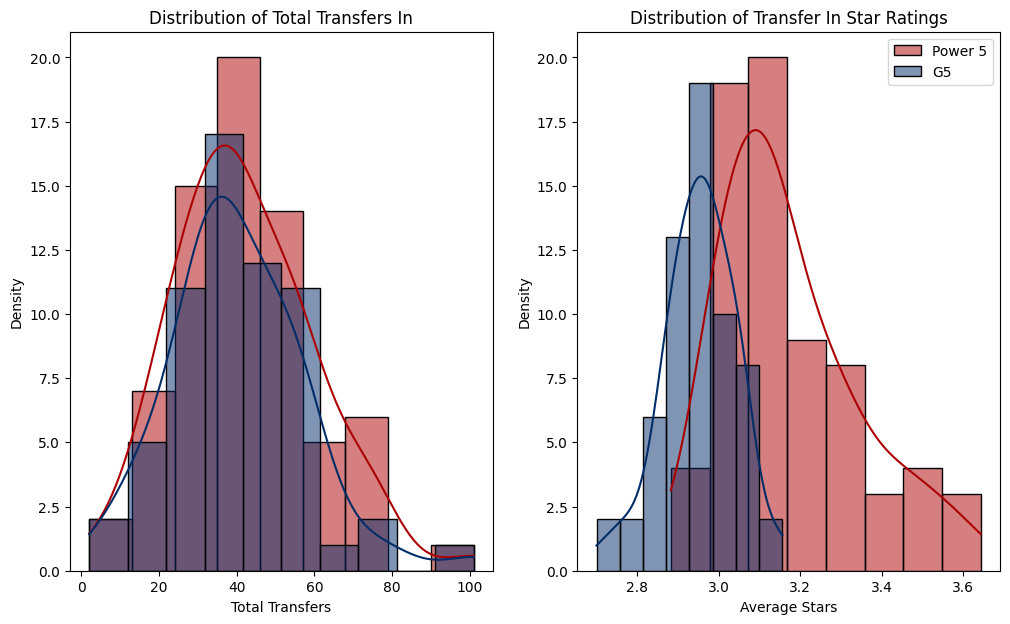
Cohen's D: 1.60This tells me that there isn’t a whole lot of difference between Power Five and G5 in the quantity of transfers that are coming in to a program, but there is a big difference in the quality of transfers coming in. The average star rating for a player going to a Power Five school is 3.17, while the average star rating for a player going to a G5 school is 2.95. Cohen’s d score for the effect size of the difference between the two is a whopping 1.6, indicating a very massive difference between the two. Generally speaking, anything over a 0.8 is considered a strong effect size. We are doubling that here.
Are G5 Schools Getting Picked Clean?
We’ve talked a good bit about transfers but what about transfers out? As we discussed earlier, however, coaches at the G5 level often claim that their teams are scavenged by larger schools. We’ve already established that there are roughly the same quantity of transfers across levels and that power conference teams tend to get the better players, but that doesn’t necessarily tell me whether or not G5 teams are losing their best players. It’s reasonable to think that the better players are already at the Power Five teams. Perhaps the player movement is just players going from P5 to P5 or from G5 to G5.
Code
transfers_out_by_conference = df[['conference', 'total_transfers_out']].groupby('conference').sum().reset_index()
plt.figure(figsize=(12, 7))
colors = ['#ad0004' if conference in power_conferences else '#012d69' for conference in transfers_out_by_conference['conference']]
bars = plt.bar(transfers_out_by_conference['conference'], transfers_out_by_conference['total_transfers_out'], color=colors)
for i, bar in enumerate(bars):
transfers_number = bar.get_height().astype(int)
plt.text(bars[i].get_x() + bars[i].get_width() / 2, bars[i].get_height() + 10, transfers_number,
ha='center', va='bottom', color='black')
plt.xticks(rotation=45)
plt.xlabel('Conference')
plt.ylabel('Total Transfers')
plt.title('Transfers Out by FBS Conference')Text(0.5, 1.0, 'Transfers Out by FBS Conference')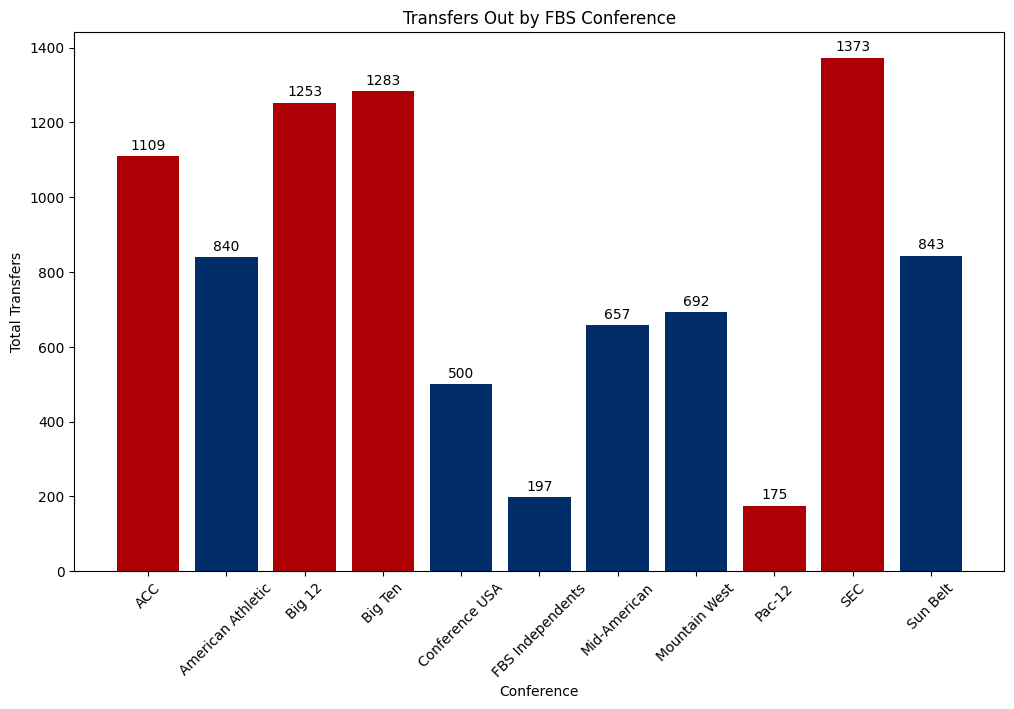
Another surprise here from this chart. I would have expected that power conference teams have less roster turnover from the transfer portal. My thinking was that the players are at or near the pinnacle of college football, so they would be more likely to stay. That does not appear to be the case. There are far more players transferring out of the Power 5 than there are players transferring out of the lower levels of FBS.
One thing that I think is interesting to note here is that there are a lot more players transferring out of FBS than are transferring in to FBS. This tells me that there are a lot of players going to FCS, DII, DIII, or NAIA schools. Hold on to this thought. I’m going to come back to that in a second.
So, how about the quality of the players transferring out? I think it is important to think about the quality of players that are already at each level again. P5 schools are going to naturally have better quality players. But if there is some similarity to level of player transferring out between P5 and G5, then it lends some credence to the idea that G5 teams are getting poached.
Code
transfers_out = pd.DataFrame(transfer_dicts) # Remake transfers data frame without aggregation
transfers_out = transfers_out.dropna(subset=['origin', 'destination'])
transfers_out = transfers_out.groupby('origin').agg({'stars': 'mean', 'season': 'count'}).rename({'season': 'total_transfers_out', 'stars': 'avg_stars'}, axis=1).reset_index()
transfers_out = transfers_out.merge(teams_df[['id', 'school', 'conference']], how='inner', left_on=['origin'], right_on=['school']).drop('school', axis=1)
power_five_transfers = transfers_out[transfers_out['conference'].isin(power_conferences) | transfers_out['origin'].str.contains('Notre Dame')]
g5_transfers = transfers_out[~transfers_out['conference'].isin(power_conferences) & ~transfers_out['origin'].str.contains('Notre Dame')]
#Scatter plots
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12, 7))
ax[0].scatter(power_five_transfers['avg_stars'], power_five_transfers['total_transfers_out'], alpha=0)
for x0, y0, id in zip(power_five_transfers['avg_stars'], power_five_transfers['total_transfers_out'], power_five_transfers['id']):
ab = AnnotationBbox(get_image_path(id), (x0, y0), frameon=False)
ax[0].add_artist(ab)
ax[0].axvline(power_five_transfers['avg_stars'].mean(), color='gray', linestyle='--')
ax[0].axhline(power_five_transfers['total_transfers_out'].mean(), color='gray', linestyle='--')
ax[0].set_xlabel('Average Stars')
ax[0].set_ylabel('Total Transfers Out')
ax[0].set_xlim(2.5, 3.5)
ax[0].set_ylim(4.5, 110)
ax[0].set_title('Power Five Transfers Out (2021-2024)')
ax[0].grid(True)
ax[1].scatter(g5_transfers['avg_stars'], g5_transfers['total_transfers_out'], alpha=0)
for x0, y0, id in zip(g5_transfers['avg_stars'], g5_transfers['total_transfers_out'], g5_transfers['id']):
ab = AnnotationBbox(get_image_path(id), (x0, y0), frameon=False)
ax[1].add_artist(ab)
ax[1].axvline(g5_transfers['avg_stars'].mean(), color='gray', linestyle='--')
ax[1].axhline(g5_transfers['total_transfers_out'].mean(), color='gray', linestyle='--')
ax[1].set_xlabel('Average Stars')
ax[1].set_ylabel('Total Transfers Out')
ax[1].set_xlim(2.5, 3.5)
ax[1].set_ylim(4.5, 110)
ax[1].set_title('G5 Transfers Out (2021-2024)')
ax[1].grid(True)
# Distribution plots
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12, 7))
sns.histplot(power_five_transfers['total_transfers_out'], label="Power 5", kde=True, color='#ad0004', alpha=0.5, ax=ax[0])
sns.histplot(g5_transfers['total_transfers_out'], label="G5", kde=True, color='#012d69', alpha=0.5, ax=ax[0])
ax[0].set_xlabel("Total Transfers")
ax[0].set_ylabel("Density")
ax[0].set_title("Distribution of Total Transfers Out")
sns.histplot(power_five_transfers['avg_stars'], label="Power 5", kde=True, color='#ad0004', alpha=0.5, ax=ax[1])
sns.histplot(g5_transfers['avg_stars'], label="G5", kde=True, color='#012d69', alpha=0.5, ax=ax[1])
ax[1].set_xlabel("Average Stars")
ax[1].set_ylabel("Density")
ax[1].set_title("Distribution of Transfer Out Star Ratings")
plt.legend()
plt.show()
# Effect power for average starts out
n_power_five = len(power_five_transfers)
n_g5 = len(g5_transfers)
std_power_five = power_five_transfers['avg_stars'].std()
std_g5 = g5_transfers['avg_stars'].std()
pooled_std = np.sqrt(((n_power_five - 1) * std_power_five**2 + (n_g5 - 1) * std_g5**2) / (n_power_five + n_g5 - 2))
cohens_d = (power_five_transfers['avg_stars'].mean() - g5_transfers['avg_stars'].mean()) / pooled_std
print(f"Cohen's D: {cohens_d:.2f}")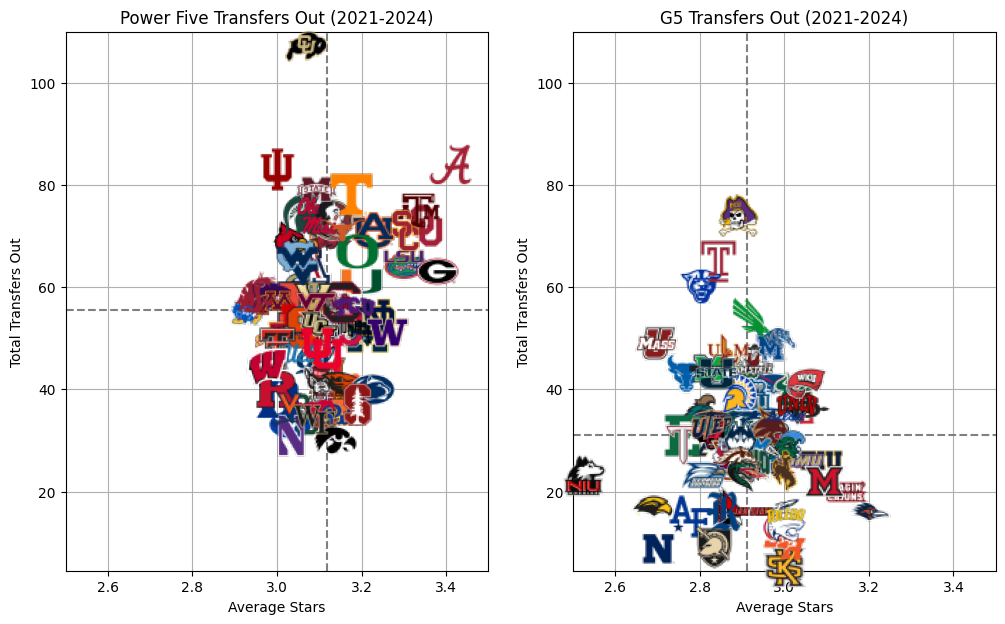
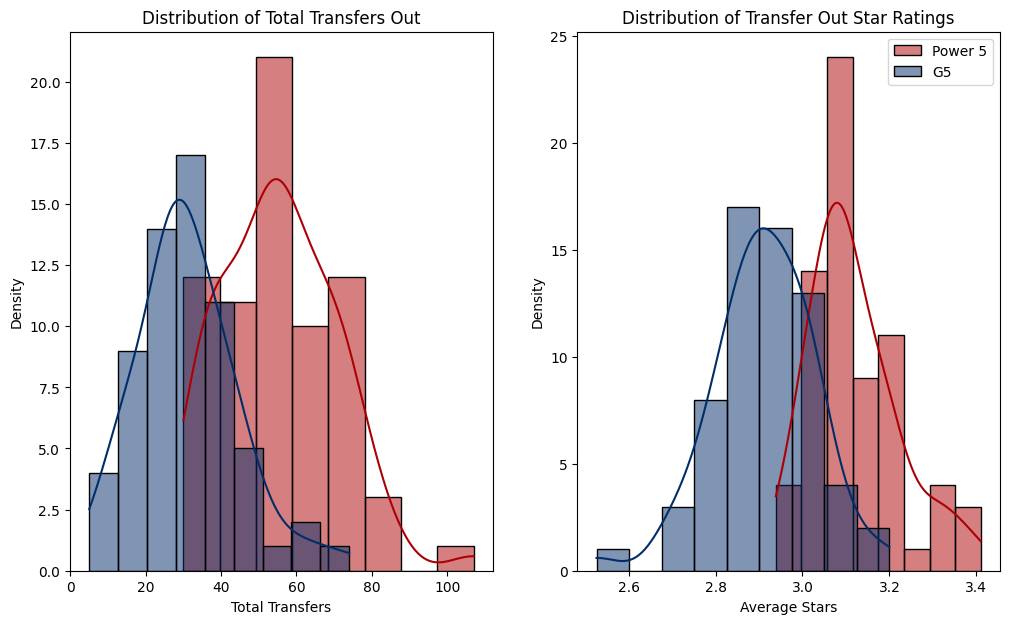
Cohen's D: 1.89So, we can tell for certain that there are more players transferring out of the Power Five than there are players transferring out of the G5, and that those players who are leaving the P5 are better. That is to be expected. Perhaps more importantly, however, is the Cohen’s D value that we are getting. The effect size of players transferring in was 1.6 indicating stronger players coming in to Power 5 schools. The effect size of players transferring out of Power 5 schools is even strong at 1.89.
Code
transfers_in = transfers.rename({'avg_stars': 'avg_stars_in'}, axis=1)
transfers_out = transfers_out.rename({'avg_stars': 'avg_stars_out'}, axis=1)
transfers_by_team = transfers_in.merge(transfers_out, how='left', on='id').drop(['conference_y', 'origin'], axis=1).rename({'conference_x': 'conference', 'destination': 'team'}, axis=1)
transfers_by_team['net_stars'] = transfers_by_team['avg_stars_in'] - transfers_by_team['avg_stars_out']
transfers_by_team['net_transfers'] = transfers_by_team['total_transfers_in'] - transfers_by_team['total_transfers_out']
p5_transfers = transfers_by_team[transfers_by_team['conference'].isin(power_conferences) | transfers_by_team['team'].str.contains('Notre Dame')]
g5_transfers = transfers_by_team[~transfers_by_team['conference'].isin(power_conferences) & ~transfers_by_team['team'].str.contains('Notre Dame')]
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12, 7))
ax[0].scatter(p5_transfers['net_transfers'], p5_transfers['net_stars'], alpha=0)
for x0, y0, id in zip(p5_transfers['net_transfers'], p5_transfers['net_stars'], p5_transfers['id']):
ab = AnnotationBbox(get_image_path(id), (x0, y0), frameon=False)
ax[0].add_artist(ab)
ax[0].set_xlabel('Net Transfers')
ax[0].set_ylabel('Net Average Stars')
ax[0].set_title('Power Five Net Transfers (2021-2024)')
ax[0].axhline(0, color='red', linestyle='--')
ax[0].axvline(0, color='red', linestyle='--')
ax[0].set_xlim(-55, 70)
ax[0].set_ylim(-0.3, .5)
ax[0].grid(True)
ax[1].scatter(g5_transfers['net_transfers'], g5_transfers['net_stars'], alpha=0)
for x0, y0, id in zip(g5_transfers['net_transfers'], g5_transfers['net_stars'], g5_transfers['id']):
ab = AnnotationBbox(get_image_path(id), (x0, y0), frameon=False)
ax[1].add_artist(ab)
ax[1].set_xlabel('Net Transfers')
ax[1].set_ylabel('Net Average Stars')
ax[1].set_title('G5 Net Transfers (2021-2024)')
ax[1].axhline(0, color='red', linestyle='--')
ax[1].axvline(0, color='red', linestyle='--')
ax[1].set_xlim(-55, 70)
ax[1].set_ylim(-0.3, .5)
ax[1].grid(True)
plt.show()
print(f"Power Five Average Net Transfers: {p5_transfers['net_transfers'].mean()}")
print(f"G5 Average Net Transfers: {g5_transfers['net_transfers'].mean()}")
print(f"Power Five Average Net Stars: {p5_transfers['net_stars'].mean()}")
print(f"G5 Average Net Stars: {g5_transfers['net_stars'].mean()}")
Power Five Average Net Transfers: -13.557142857142857
G5 Average Net Transfers: 8.370967741935484
Power Five Average Net Stars: 0.05454902936543176
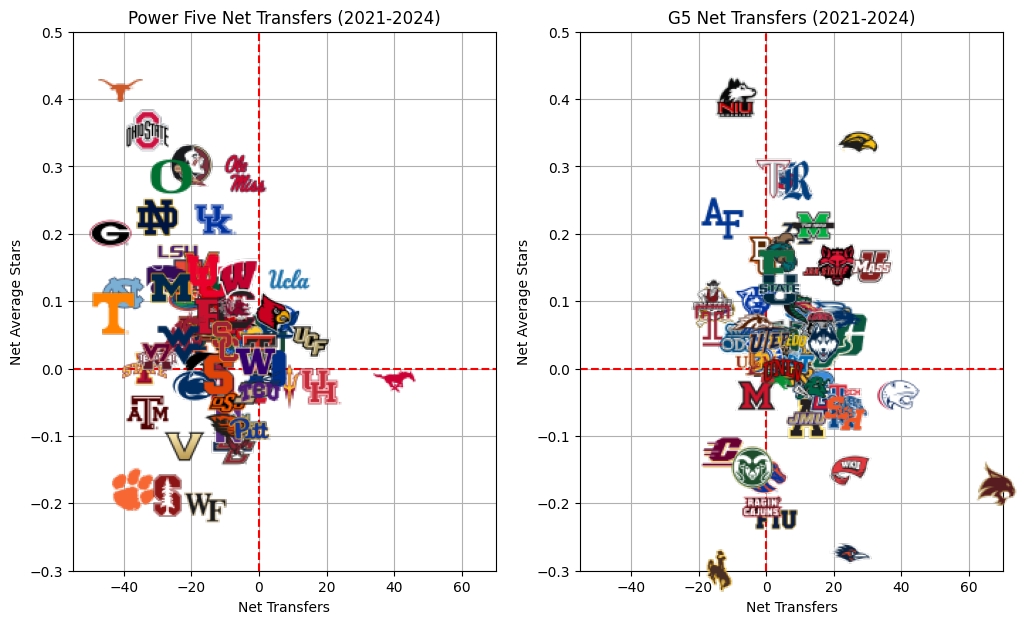
G5 Average Net Stars: 0.03710712681054378The above plot summarizes my point the best: on a single-player basis, the top end of the Power Five teams are gaining stars. If you pick a random player from a CFP contender, they may be a four or five star while if you pick a random player from an average C-USA team, they might be a two or three star.
On the aggregate, however, Group of Five teams are outperforming Power Five teams in the transfer portal. Most P5 programs are losing more players to the portal than they are bringing in, while most Group of Five teams are bringing in more transfers than are leaving their teams. And the players that are coming in to the G5 schools are generally better than those that left.
Power Five schools are losing, on average, 13.56 players to the transfer portal each year while Group of Five teams are gaining 8.37 players per year. So while the average stars of the players coming in to a P5 school is increasing, the number of bodies available for that team, through the transfer portal, is decreasing. Meanwhile, G5 schools are actually getting more, better players through the transfer portal.
Who is Really Hurt By This?
Given all of this information, I think the noise being made my G5 coaches about their players being poached is largely overstated. I understand the want for continuity and keeping players in your system. However, this data tells me that G5 schools are fairing much better in the transfer portal than power conference teams.
Who really has a right to be throwing a fit are the high school players who are yet to play a down of college football. There are only so many roster spots available in college football and not everyone is a blue chip recruit. Most of them are two or three star kids. If the players that didn’t make it at the P5 level are going to the G5, and the P5 schools are backfilling with blue chip guys, what happens to those two and three star players? Surely some of them will go to the Wyoming and Central Michigan’s of the world - the G5 teams with net negative transfers. But most of them will need to move down FCS or DII.
There is nothing wrong with playing at that level of football. I went to an FCS school and a handful of the players on the football team while I was there ended up in the NFL. If you’re good enough, they will find you. But for the vast majority of players, the players who go to school, play football on a scholarship, and then get a job like you and me, the difference in level can mean thousands of dollars in scholarship money lost. FCS schools have fewer scholarships to begin with, and even then those scholarships are generally not full rides.
Conclusion
This is not an admonishment of the Transfer Portal or the state of college football. There are plenty of unknowns in the sport and navigating these uncharted waters is bound to lead to some growing pains. I think it is fair to have criticisms of unlimited player transferring. But the next time someone tells you that it is killing the Group of Five teams, you will know that that is not true.